大家好,我是大志。
上一篇文章我们聊了Agent的基础概念和ReAct、Plan-and-Execute这些核心设计范式。
本文将会带大家一起分析一下Agent架构设计。比如:什么时候用单Agent?什么时候用多Agent?多Agent之间如何通信?这些全是实际项目中经常遇到的问题,也是面试官最爱深挖的方向。
除此之外,大家也可以在线阅读完整面试题文档:aiflowline.cn
1、多Agent之间如何通信?
多Agent之间的通信方式主要有三种:
- 消息传递(
Message Passing)
Agent之间通过发送消息通信,使用这种方式Agent间通信更加灵活,Agent之间不需要知道对方的实现细节,但是token消耗很大,调试困难,上下文容易失控。
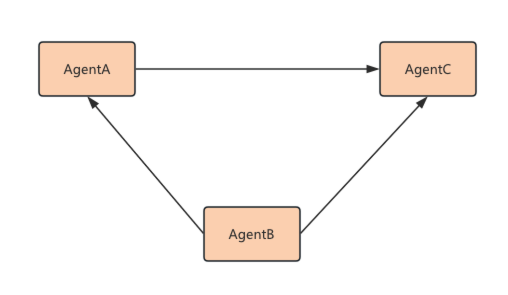
- 中心调度器(Orchestrator)+共享状态(
Shared State)
这是最常见的实现方式,在这个模式下,Agent之间不能直接通信,所有消息要经过中心调度器,并且所有Agent通过一个共享的状态对象进行交互。不同的Agent读取状态、处理任务、把结果写回状态,比如LangGraph的State。
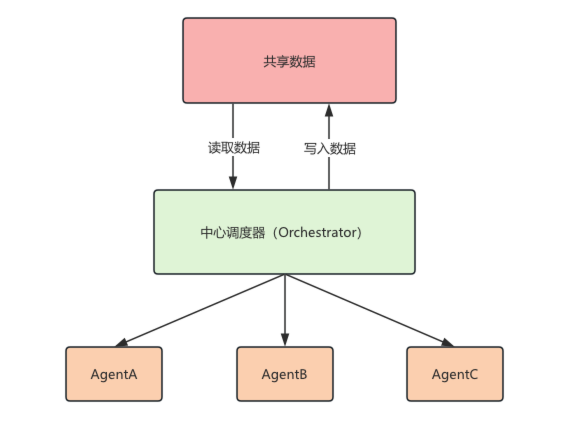
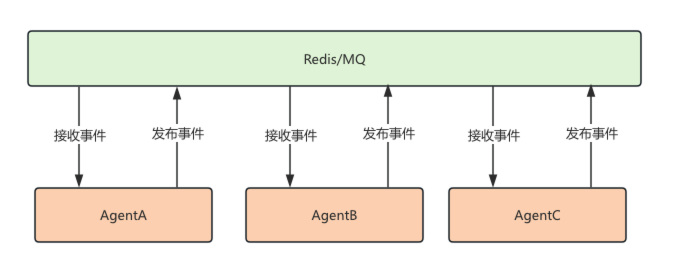
- 事件总线(Event Bus)
在复杂的系统中,会用到事件总线,比如AgentA发布事件,AgentB和AgentC订阅事件。
2、为什么选择 Orchestrator + Shared State
在生产环境中,通常采用Orchestrator + Shared State的模式。各个Agent不能直接通信,而是通过共享状态交换数据,由 Orchestrator 统一负责调度和状态流转。
这样能够避免 Agent 间形成复杂依赖,提升系统的可观测性、可恢复性和可维护性。Shared State 通常存储在 Redis 或数据库中,LangGraph 的 StateGraph 也是使用这种设计思想。
3、中心化Orchestrator和去中心化Peer有什么区别?
Orchestrator 模式:所有 Agent 不直接通信,由一个中央调度器统一协调。
Peer-to-Peer 模式:Agent 是平等的,可以直接互相通信。
两种模式对比如下:
| 维度 | 中心化 Orchestrator | 去中心化 Peer |
|---|---|---|
| 控制权 | 中央调度器 | 各 Agent |
| 通信方式 | 通过调度器 | 直接通信 |
| 调试难度 | 低 | 高 |
| 可观测性 | 高 | 低 |
| Token成本 | 较低 | 较高 |
| 扩展性 | 一般 | 强 |
| 灵活性 | 一般 | 强 |
| 死循环风险 | 低 | 高 |
| 企业生产环境 | 常见 | 较少 |
大部分业务场景用中心化的Orchestrator就够了,简单可控,出了问题也好排查。去中心化的模式在工程实践中用得比较少,主要在学术研究中出现。
4、多Agent如何共享上下文?
多Agent共享上下文是架构设计中的核心问题,常见的方案有:
- 共享状态对象(Shared State)
所有Agent共享一个State,每个Agent在执行时可以读取和写入这个状态。比如在LangGraph就是这么做的,返回数据时,进行State数据的更新。
# 共享状态定义
class AgentState(TypedDict):
task: str # 原始任务
research_result: str # Research Agent 的结果
analysis: str # Analysis Agent 的结果
report: str # Writer Agent 的结果
# 每个 Agent 都可以读写这个状态
def research_agent(state: AgentState):
result = search(state["task"])
return {"research_result": result}
def writer_agent(state: AgentState):
report = generate_report(state["research_result"], state["analysis"])
return {"report": report}- 共享记忆
把Memory作为共享上下文,每个Agent都能看到这些共享的记忆信息。
- 共享 Workspace
多个 Agent 共同操作文件系统的工作空间,其实就是通过共享的文件来作为多Agent的上下文,这种实现方式,尤其在AI编程相关的Agent中使用得非常多。
- 消息传递
Agent之间通过发送消息,把消息作为上下文。
5、多Agent如何避免循环调用?
循环调用是多Agent系统中最常见的问题,Agent A 调 Agent B,Agent B 又调 Agent A,陷入死循环。
最直接的办法是给整个流程设一个上限。比如最多执行25步,超过就强制终止:
# LangGraph 的做法
app = graph.compile(checkpointer=checkpointer)
result = app.invoke(input, config={"recursion_limit": 25})还可以设置单向状态流,限制Agent之间的调用关系,比如规定Agent A只能调用Agent B,顺序不能反过来:
def router(state):
last_agent = state["last_agent"]
if last_agent == "agent_a":
return "agent_b" # A 之后只能去 B
elif last_agent == "agent_b":
return "end" # B 做完就结束,不能回到 A设置总的token预算或超时时间放到共享数据中,一旦达到设定阈值就终止:
if state["total_tokens"] > MAX_TOKENS:
return "force_end"6、如何设计Agent角色分工?
设计Agent角色分工的本质是:把复杂任务拆解成多个职责明确、能力单一的Agent协同完成。
设计Agent角色分工的核心原则有四个:
- 单一职责(Single Responsibility)
每个Agent只负责做一件事情,例如开发一个AI编程助手,其中
Planner Agent:负责任务拆解
Coder Agent:负责代码生成
Reviewer Agent:负责代码审查
每个Agent职责单一,可以让Prompt更简单,输出更稳定,如果让一个Agent同时规划、编码、测试、审查,一个Prompt干四件事,模型容易出现:计划不完整、代码质量差等问题。
- 按能力边界拆分
Agent应该按照能力边界拆分,例如:
Research Agent:负责搜索
Writer Agent:负责写作
Reviewer Agent:负责审核
因为三者能力完全不同。
- 高内聚,低耦合
Agent之间尽量减少依赖。Researcher只关心搜索,不关心文章怎么写。
Writer只关心根据资料生成内容,不关心资料从哪里来的,这样后续替换和扩展Agent非常容易。
- 按流程拆分
把业务流程切成多个阶段。例如招聘系统:
简历解析Agent
↓
岗位匹配Agent
↓
面试评估Agent
↓
Offer生成Agent每个Agent负责流程中的一个环节。
7、如何从业务需求推导Agent架构?
设计Agent架构时,遵循需求拆解 → 角色划分 → 设计协作方式的思路。
- 首先将业务需求拆解成多个子任务,然后分析哪些环节需要推理和决策能力,哪些环节可以通过传统代码或API完成。并不是所有问题都适合Agent。
- 对于规则明确、逻辑固定的任务,通常直接使用代码实现即可。
- 接下来判断应该采用单Agent还是多Agent。如果任务简单、工具较少、流程固定,单Agent即可。
- 如果任务涉及多个领域、职责明显不同,则更适合采用多Agent架构。
最后,设计Agent之间的协作方式。生产环境中通常采用 Orchestrator + Shared State 模式,由调度器统一管理流程,通过共享状态交换上下文,并增加重试、超时、人工介入等兜底机制。
8、如何设计Agent状态流转?
Agent状态流转本质上是状态机设计,需要明确系统有哪些状态、状态之间如何转换,以及在什么条件下结束执行。
每个状态对应不同职责,比如:
- PLAN:任务规划
- EXECUTE:任务执行
- REVIEW:结果检查
- DONE:任务完成
在设计状态流转时,需要重点考虑:
- 状态切换条件。需要明确每个状态在什么条件下进入下一个状态。
- 异常处理流程。实际生产环境不能只考虑正常路径,还需要设计重试、降级、转人工等异常流转。
- 终止条件。例如达到最大重试次数、超过Token预算、执行超时等。
在LangGraph中,状态流转通常通过 State、Edge 和 Conditional Edge 实现,本质上就是一个可编排的状态机。
9、如何设计Human-in-the-Loop流程?
Human-in-the-Loop(HITL)指在Agent执行过程中引入人工参与,让系统在关键节点暂停并等待人工决策,也称为人在环路。在使用人在环路时,要遵循“低风险自动执行,高风险人工确认”的原则,Agent需要保存当前状态,在人工审批完成后继续执行。
人在环路出现的主要原因是因为Agent并不总是可靠的,对于高风险的操作需要人工确认。例如:
- 退款
- 转账
- 删除数据
- 发布上线
- 合同审批
比如在涉及转账操作时,流程如下:
确认打款金额
↓
人工审核
↓
批准/拒绝/修改
↓
继续执行在LangGraph中,实现人在环路可以通过 interrupt() 进行暂停,通过 Command(resume=...) 恢复执行。
10、如何确保一个 Agent 的行为是安全、可控且符合人类意图的?在 Agent 的设计中,有哪些保障对齐方法?
要让 Agent 安全、可控、符合人类意图,不能只依赖模型本身,而要从 权限控制、工具约束、流程控制、人工审核、结果校验、监控审计 几个层面一起设计。
- 明确 Agent 的能力边界
首先要限制 Agent 能做什么、不能做什么。Agent 的系统提示词中也要明确角色、职责、禁止行为和输出要求,但提示词只能作为软约束,不能作为唯一安全机制。例如:能读取知识库,但不能访问无权限的数据。
- 工具权限控制
Agent 真正影响外部世界,通常是通过工具调用完成的,所以工具权限控制非常关键。常见做法包括:给不同 Agent 分配不同工具权限、对高风险工具做白名单限制、对工具参数做校验、对敏感操作增加审批、禁止 Agent 直接执行任意代码或任意命令。
例如:
def refund_order(order_id: str, amount: float):
if amount > 1000:
raise PermissionError("大额退款需要人工审核")
return do_refund(order_id, amount)这样即使模型产生了错误决策,工具层也能拦住危险操作。
- Human-in-the-Loop(人在环路)
对高风险操作必须引入人工确认。比如:转账、退款、删除数据、发布上线、修改权限、发送邮件或合同。
以转账操作为例,流程大概如下:
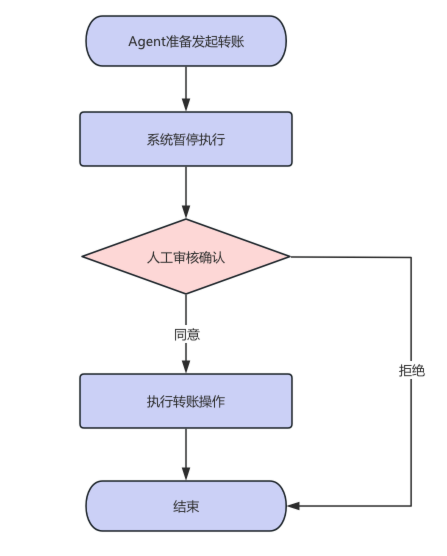
- 状态机和流程约束
Agent 的执行流程要通过状态机控制,不能让模型自由决定所有执行流程。只有满足条件才能进入下一个状态。如果抛出错误或者结果不满足要求,就进入重试、修正或人工处理,这样可以避免 Agent 跳过审核、重复执行、陷入循环调用。
- 输出校验和结果审查
Agent 的输出需要经过校验,尤其是结构化输出、代码生成、SQL生成等场景。常见方式包括:JSON Schema 校验、规则引擎校验、单元测试或静态检查、引入另一个 Reviewer Agent 审核、关键字段和业务规则校验。例如让 Agent 输出 JSON 时,需要校验字段是否完整、类型是否正确。
- 监控、审计和可回滚
生产环境中的 Agent 系统必须具备可观测性。在系统中需要记录:用户输入、Agent 决策过程、工具调用参数、工具调用结果、状态流转、人工审批记录、错误和重试信息,这样出问题时才能定位原因。
好啦,今天这期Agent架构面试题就到这里。后面我会每周至少更新1期面试题系列,想看后续 【AI Agent进阶面试题】 的朋友,欢迎关注「大志说编程」!
觉得有用的话,转发给正在面试的小伙伴,咱们下期见~